Oferta actual de TFG/TFM
Llevo trabajando varios años, en colaboración con otras universidades y empresas nacionales y europeas, en el desarrollo de sistemas de sensorización (cámaras, móviles, pulseras inteligentes) para la monitorización de personas para el hogar. En particular, estos sistemas de visión se han empleado para mejorar la calidad de vida y apoyar la vida independiente y saludable de personas mayores. En la actualidad, lidero los proyectos internacionales visuAAL - Privacy-Aware and Acceptable Video-Based Technologies and Services for Active and Assisted Living y GoodBrother - Network on Privacy-Aware Audio- and Video-Based Applications for Active and Assisted Living.
Dentro de estas líneas de trabajo, este año propongo los siguientes TFG/TFM:
- Desarrollo de un sistema de vision estéreo empleando un par de cámaras omnidireccionales
- Determinación de la postura de una persona empleando una cámara situada en el techo
- Estimación de constantes vitales con una cámara
- Estimación de emociones empleando una pulsera inteligente
- Reconocimiento de acciones de la vida diaria con una pulsera inteligente avanzada
- Reconocimiento de actividades con una cámara térmica de baja resolución
- Studying the fairness provided by visual obfuscation algorithms
- Vide-ómica: Aceleráción del uso de técnicas de la genómica a la visión por computador
- Creación de dataset para segmentación de la piel empleando una red neuronal profunda
- Implementación de GAN (Generative Adversarial Network) para obtener una imagen "cartoonizada" para proteger la privacidad de un entorno monitorizado
Dado que en el equipo de trabajo hay investigadores extranjeros, la supervisión de algunos de estos trabajos podría ser en inglés, si se está interesado.
Si tienes alguna otra idea relacionada con el empleo de sensores para monitorizar a personas, dar servicios a personas mayores o en situación de fragilidad, ponte en contacto conmigo para discutirla.
Desarrollo de un sistema de vision estéreo empleando un par de cámaras omnidireccionales
Dentro del trabajo en los proyectos de investigación visuAAL y GoodBrother, se pretende reconocer las acciones de personas observadas con cámaras situadas en el techo. Para ello, es necesario obtener y realizar un seguimiento de su postura a lo largo del tiempo. La estimación de la postura se facilita si se tiene información tridimensional de la escena. Por ello, se plantea desarrollar un sistema, de bajo coste, que combine varias cámaras omnidireccionales para obtener información de profundidad de la habitación. Un sistema similar al de la Omni Stereo camera. Este sistema estéreo también permitirá obtener información 3D del entorno. Los objetivos concretos son:
- Construcción de un sistema que combine dos cámaras omnidireccionales. En principio, se considerará el incorporar dos cámaras D-Link DCS 6010L o similar (la cámara D-Link está descatalogada y hay actualmente cámaras similares más baratas), unidas mediante una estructura
- Calibración del sistema estéreo
- Implementación de un caso de uso en el entorno del hogar

Determinación de la postura de una persona empleando una cámara situada en el techo
Recientemente, ha crecido el interés en dispositivos asequibles como Microsoft Kinect o ASUS Xtion Pro, que pueden capturar la profundidad a la que se encuentran personas y objetos con bastante fiabilidad. Estos sensores de imagen proporcionan una imagen de profundidad (D), además de la típica imagen en color (RGB). Estos datos RGB-D pueden utilizarse para obtener una estimación de la pose del cuerpo sin utilizar marcadores. En concreto, se genera un modelo de esqueleto que consiste en un conjunto de articulaciones. Estos datos característicos se pueden utilizar para aprender y clasificar poses humanas, acciones o incluso actividades de la vida diaria (ADLs). Estos sensores de profundidad se han vuelto populares debido a su alta velocidad de muestreo, bajo coste y la capacidad de combinar información visual y la profundidad. Su uso se puede encontrar tanto en aplicaciones comerciales como de investigación. Sin embargo, la obtención de este esqueleto y la estimación de la postura de una persona es mucho más compleja empleando cámaras convencionales RGB, ya que al no contar con datos de profundidad es más complejo segmentar la persona del resto de la imagen. Esta segmentación es, además, más difícil en un entorno como el hogar en el que muebles y objetos pueden tapar parte del cuerpo. En los últimos años han aparecido diferentes librerías para obtener la postura de una persona empleando cámaras convencionales. Entre ellas, encontramos DeepPose. Sin embargo, los resultados empleando estos métodos no son adecuados cuando las personas son vistas desde arriba. Asimismo, el uso de cámaras con ópticas de ojo de pez crean distorsiones que modifican las distancias entre las diferentes articulaciones de las personas. Este trabajo plantea la determinación de la postura de una persona a partir de imágenes tomadas con una cámara situada en el techo de una habitación. En la actualidad, se está grabando un dataset con múltiples vídeos de personas en diferentes situaciones habituales en el hogar: preparación de comida, ver la tele, higiene personal, descanso,... con diferentes dispositivos RGB y RGB-D sincronizados: Kinects y una cámara omnidireccional situada en el techo de la habitación. Los vídeos se están grabando en viviendas particulares. Se espera contar con un número elevado de vídeos que permitan tener suficientes datos como para emplear métodos de deep learning para una variedad de aplicaciones. El objetivo es estimar el esqueleto de la persona, y por tanto su postura, a partir de las imágenes RGB capturadas con la cámara situada en el techo. Para ello, se empleará como resultado que se debería obtener por el sistema los datos de postura (esqueletos) obtenidos con las Kinect que están sincronizadas con esa cámara. El principal problema son las oclusiones producidas por el propio cuerpo cuando la persona está situada justo debajo de la cámara, en las que la cabeza y el tronco tapan las piernas, por lo que se debe estimar su posición.
Estimación de constantes vitales con una cámara
En este trabajo se pretende estimar las constantes vitales (frecuencias cardiaca y respiratoria) de un individuo que se encuentra frente a una cámara de vídeo. Ver este vídeo para un ejemplo. Los objetivos concretos son:
- Búsqueda de códigos disponibles para estimación de constantes vitales.
- Integración y validación
- Implementación de nuevos algoritmos
Estimación de emociones empleando una pulsera inteligente
Las reacciones emocionales humanas a los estímulos proporcionados por diferentes modalidades sensoriales son un tema de interés para muchas disciplinas, desde la interacción hombre-computadora hasta las ciencias cognitivas. Es conocido que cambios en el estado emocional provocan un incremento del ritmo cardiaco, dilatación de las pupilas, cambios en la tensión muscular y en la respuesta galvánica de la piel. En un TFG previo se implementó una aplicación que captura diferentes señales fisiológicas al mismo tiempo que se generan emociones determinadas en una persona. Para ello, se emplea la pulsera Empatica E4, mientas se muestran al usuario imágenes que generan emociones conocidas, como miedo, alegría, etc.. Los objetivos concretos son:
- Captura de un dataset, empleando la aplicación desarrollada en un TFG previo.
- Tratamiento del dataset
- Desarrollo y validación de un algoritmo para la estimación de emociones

Reconocimiento de acciones de la vida diaria con una pulsera inteligente avanzada
Los países europeos y otros países alrededor del mundo se enfrentan a retos cruciales en materia de salud y asistencia social debido al cambio demográfico y al contexto económico actual. La innovación en tecnologías y servicios para la Vida Activa y Asistida (Active and Assisted Living - AAL) destaca como una solución prometedora para abordar estas demandas sanitarias y sociales a la vez que para aprovechar las oportunidades económicas derivadas de estas necesidades. Los sistemas AAL hacen uso de una variedad de sensores para monitorizar a las personas y su entorno con el fin de mejorar la calidad de vida y apoyar la vida independiente y saludable de personas mayores o discapacitadas en su hogar, en su lugar de trabajo y en espacios públicos. Los recientes avances en sistemas de computación portados por el usuario, con una miríada de productos en el mercado (por ejemplo, cámaras, relojes, pulseras y gafas inteligentes), el aumento de la funcionalidad de dispositivos y aplicaciones móviles para la salud y el bienestar, y la instalación más sencilla y barata de sistemas domóticos están contribuyendo a la adopción de servicios de salud y de vida asistida por una mayor parte de la población. Por ejemplo, las tecnologías de lifelogging (también conocidas como quantified self o self-tracking) pueden permitir y motivar a las personas a adquirir de una manera continua y ubicua datos sobre ellos, sobre su entorno y sobre las personas con las que interactúan. La adquisición y el procesamiento de señales fisiológicas (por ejemplo, la frecuencia cardíaca, la frecuencia respiratoria, la temperatura corporal y la conductancia de la piel), el movimiento, la ubicación, las actividades realizadas, las imágenes vistas y los sonidos escuchados son la base para la provisión de una variedad de servicios de vanguardia para aumentar la salud, el bienestar y la independencia de las personas. Ejemplos de estos servicios incluyen atención médica personalizada, seguimiento del bienestar (actividad física, hábitos alimenticios), apoyo a personas con problemas cognitivos, participación social, movilidad, apoyo a cuidadores formales e informales, sistemas predictivos (disminución cognitiva, conductas agresivas, prevención de caídas). Entre los sensores que se utilizan para crear un lifelog de la persona se encuentran las pulseras inteligentes. Se dispone de una pulsera Empatica E4. En un TFG previo se ha capturado un dataset de personas realizando actividades cotidianas. En este proyecto, se pretente reconocer las actividades de la vida diaria que realiza una persona, con el objetivo de proveer información tanto a ella como a sus familiares y cuidadores. Para ello, se implementarán sistemas de aprendizaje máquina, empleando modelos neuronales profundos (deep learning), para determinar las actividades que una persona realiza en función de los datos adquiridos con los múltiples sensores de la Empatica E4.
Reconocimiento de actividades con una cámara térmica de baja resolución
En este trabajo se plantea el reconocimiento de actividades de la vida diaria, como cocinar, comer, lavarse, ver la televisión, etc. Con una cámara térmica de baja resolución. Por ejemplo, la Panasonic Grid-EYE tiene una resolución de 8x8. Esto permite estimar lo que ocurre en la escena al mismo tiempo que se protege la privacidad de las personas monitorizadas, debido a la baja resolución. Los objetivos concretos son:
- Captura de un dataset de actividades con la cámara térmica de baja resolución.
- Implementación y validación de un algoritmo para el reconocimiento de actividades
Studying the fairness provided by visual obfuscation algorithms
Visual obfuscation algorithms aim to provide privacy to people captured in photos and videos. These are of two types. Classical literature has focussed on the first type, perceptual obfuscation algorithms, which aim to perceptually alter images in a way that privacy sensitive elements in images are protected from humans who view the frames without the necessary access privileges. Thus bodily privacy is imparted to the monitored people. The simplest examples of these are pixelation and blurring, and a large number of variants do exist with the state-of-the-art relying on deep learning for obfuscation. The second type is called machine obfuscation. These aim to hide the subjects in the visuals from machine learning algorithms which use the images without permission for training purposes. Machine obfuscation algorithms aim to create images that are perceptually similar to the original, while masking the subject from algorithms. These typically use generative adversarial networks, a class of deep learning algorithms to get the necessary effect. While a large body of literature is present on the creation of these methods, results are scant when it comes to knowing whether the algorithms are fair towards people who fall outside the bell curve in terms of demographics. For example, it is unknown whether a facial recognition algorithm would provide similar results on obfuscated images of a Caucasian male versus that of an Asian female. Biases are expected to exist, as the datasets used for training recognition algorithms largely contain Caucasian males. The student is expected to study the literature in privacy preservation methods for RGB images and videos, and observe the fairness of a select number of perceptual and machine obfuscation algorithms. They are also expected to come up with solutions to solve the problem of unfair algorithms if it exists, by creating fairer obfuscation algorithms

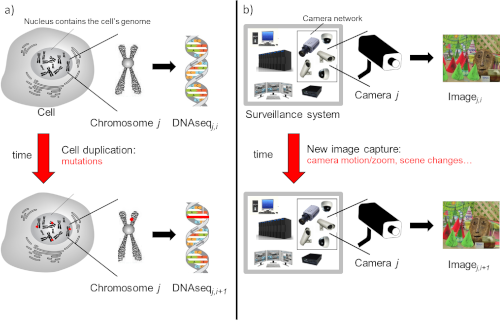
Vide-ómica: Aceleráción del uso de técnicas de la genómica a la visión por computador
Se pueden establecer analogías entre datos genómicos e imágenes en términos de estructura y evolución. De manera similar a una imagen, que puede codificarse como un conjunto de cadenas de píxeles, el material genético tiene esencialmente una estructura digital lineal que está representada por cadenas de millones de caracteres, llamadas secuencias. Estas secuencias evolucionan con el tiempo a través de mutaciones de elementos individuales y grupales. Del mismo modo, un video puede interpretarse como la captura de una sola imagen que evoluciona a través del tiempo. Por lo tanto, el análisis de video podría abordarse mediante la detección y cuantificación de mutaciones de una imagen a lo largo del tiempo. Este un trabajo muy interesante, ya que combina dos campos del conocimiento diferentes y puede llegar a proporcionar un nuevo paradigma para el procesamiento de vídeo. En trabajos previos realizados junto a la Kingston University London, se ha aplicado este paradigma de la vide-ómica a stereo matching, a la eliminación de distorsiones en imágenes y a la obtención de los elementos en primer plano en vídeos en movimiento. Sin embargo, el coste computacional actual de aplicar este nuevo paradigma es muy elevado para poder aplicarlo en problemas reales, en los que se requiere rapidez en la respuesta. Si se resolviera este problema, nuestro sistema sería capaz en tiempo real, por ejemplo, de eliminar el fondo en imágenes tomadas con una cámara en movimiento, eliminar distorsiones producidas por una gota en el objetivo de una cámara,... Recientemente, se publicó un artículo divulgativo de cómo la vide-ómica pueda cambiar los sistemas de video-vigilancia. Asimismo, el éxito de este trabajo permitiría abrir una línea muy interesante de investigación no sólo en visión por computador sino también en el tratamiento de secuencias genéticas. El objetivo de este trabajo es sustituir el algoritmo de Needleman-Wunsch que se emplea usualmente para alinear secuencias genómicas. Para ello, se diseñará, implementará y validará una red neuronal que tome como entrada un par de secuencias y aporte como salida el alineamiento entre ambas. Para ello, se necesitará una cantidad masiva de datos para entrenar dicha red neuronal, datos que serán obtenidos a lo largo de este trabajo.
Creación de dataset para segmentación de la piel empleando una red neuronal profunda
En este trabajo se plantea la creación de un dataset para el entrenamiento de sistemas de deep learning para la segmentación de las partes de la imagen que corresponden a piel de las personas (skin segmentation). Esto permitirá, posteriormente, estimar el grado de desnudez de una persona. No existen en la actualidad datasets de suficiente tamaño para entrenar sistemas de deep learning. Por ello, hemos planteado el crear datasets para skin segmentation a partir de datasets de prendas de ropa, entendiendo que la piel son las zonas de las personas que no están cubiertas ni de ropa ni de pelo. Hemos creado uno recientemente que está disponible en https://zenodo.org/record/6973396. Detalles de cómo se ha construido pueden obtenerse en https://link.springer.com/chapter/10.1007/978-3-031-13321-3_6. Este dataset tiene 46.775 imágenes. Sin embargo, existen otros datasets de prendas de ropa que tienen un tamaño mayor, aunque presentan problemas, como que no todas las prendas están etiquetadas. Recientemente se ha implementado un modelo neuronal con mecanismos de atención que permiten reconocer las áreas de piel mejor que métodos anteriores. En este trabajo se pretende emplear esto nuevo modelo neuronal para crear un nuevo dataset para skin segmentation a partir de un dataset de prenda de ropa de mayor tamaño.

Implementación de GAN (Generative Adversarial Network) para obtener una imagen "cartoonizada" para proteger la privacidad de un entorno monitorizado
En este trabajo se plantea el empleo de redes generativas antagónicas (Generative adversarial networks - GANs) para proteger la privacidad del entorno en el que se mueve una persona que está siendo monitorizada con cámaras. En trabajos previos, el grupo ha trabajado en proteger la privacidad de la persona monitorizada. En este caso, se pretende proteger el entorno que también aparece en la imagen. Para ello, se pretende generar una imagen "cartoonizada" de la imagen original que permita estimar cómo es el entorno, pero en la que no se puedan ver detalles. Este "filtro" se ha implementado ya sin emplear deep neural networks, siguiendo un proceso similar al mostrado en https://www.analyticsvidhya.com/blog/2022/06/cartoonify-image-using-opencv-and-python. En este trabajo se pretende inicialmente obtener un resultado similar con una GAN. Uno de los requisitos es que debe obtenerse rápidamente para poder obtener la frecuencia del vídeo.






